Clustering: How much does it differ from Load Balancing?

A cluster can be defined as a group of stuff. Likewise, a computer cluster is a group of computers that works for a common goal. The functionality of clustering is to divide workloads among the computers that act like nodes so that their combined memory and processing power of them all together gives a better overall performance.
All the nodes in a cluster are connected to a network where they form an internode connection and later form a cluster. They even might have shared storage or local storage on each node.
On a cluster, there is always one node that acts as a leader and is an entry point for the cluster. It delegates the tasks to the other fellow nodes and sometimes even returns the result to the user. The whole cluster works like a single system and there is no way for the user to know if they are interacting with a cluster or an individual machine. The clusters lead to low latency and prevent bottlenecks in node-to-node communication as well.

We can see clustering in many technologies these days. There are Kubernetes and Amazon ECS as containers, Cassandra and MongoDB as databases, and Redis as caches. There are three types of usual clusters,
- Highly Available or fail-over
- Load Balancing
- High-Performance computing
For the highly available clusters, there are two kinds of configurations. Let’s look at them individually.
Active-Active Configurations
In the active-active configurations, there are at least two nodes that work together for the same kind of service. The concept of active-active comes from load balancing that distributes the work across the devices in the group. This helps the nodes remain intact since the overload is prevented in the configuration.
In addition, some nodes are spared to be used later which can help improve throughput and response time.
Active-Passive Configurations
Further, there is an active-passive configuration where there are at least two nodes like the active-active configurations. However, the node from the active-passive cluster has a special feature. Not all nodes are active in the configuration, but some will be in passive or standby mode as well. They only come forward when the active node fails or goes passive due to any reason.

How much different is Clustering from Load Balancing?
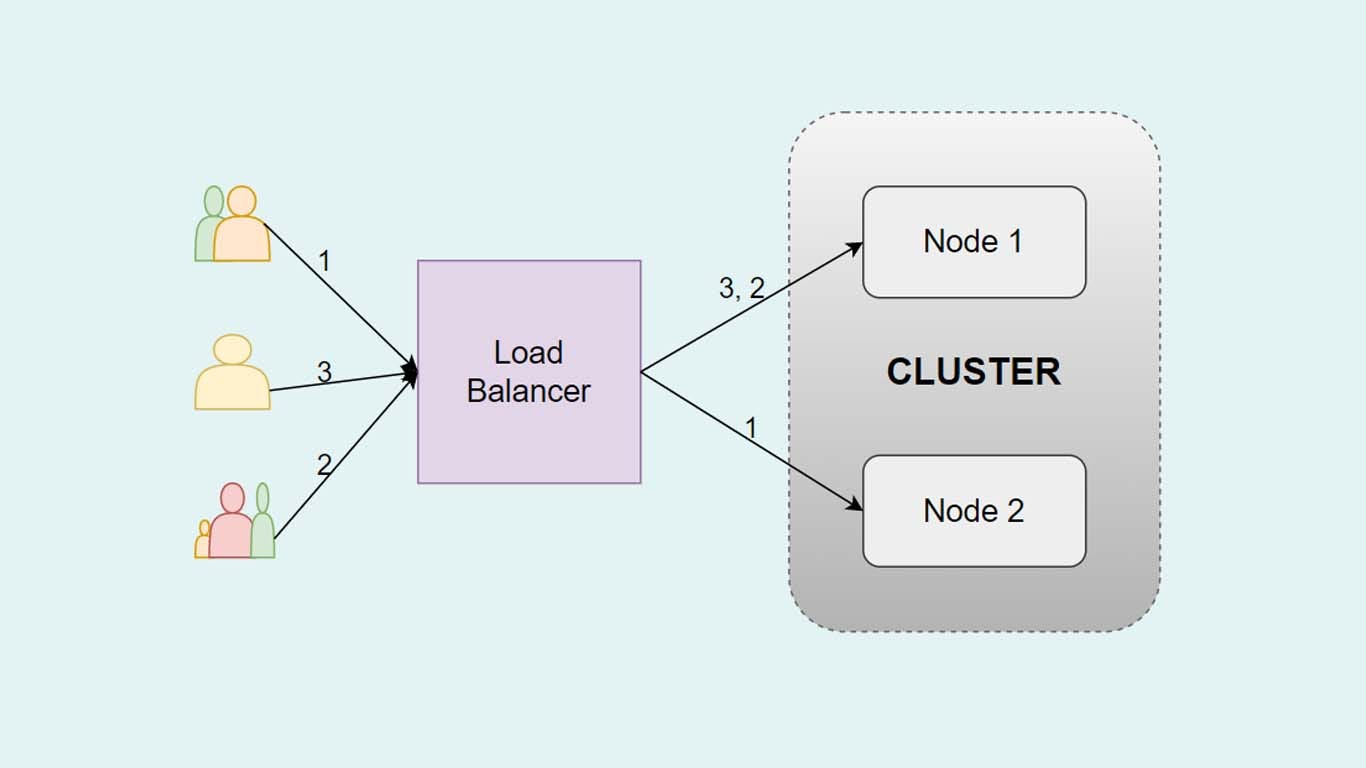
While load balancing and clustering might sound the same, they are not. They do share some common features though. While the nodes or the servers have no idea of each other’s existence in the load balancer, they are aware of the nodes in clustering. Clustering also gives us redundancy and boosts capacity and availability because all the servers work for the same goal. Likewise, the load balancer makes its node react to the requests they receive respectively.
To note, we can implement both load balancing and clustering in the system as well. It can also be in use when independent servers are for the same goal. They can be beneficial when specific web services are required.
Advantages of Clustering
- Highly Scalable
- Availability
- Improved Performance
- Low Latency
- Cost Effective
Challenges of Clustering
- More complexity for installation and maintenance
- Increased complications if the nodes are not homogenous
- Managing Storage is hard since the nodes can sometimes over-write one another in shared space
- Extra hard work — distributed data needs to be in sync always
I hope this article was helpful to you.
Please remember to applaud this article and follow me!!!
Any kind of feedback or comment is welcome!!!
You can also subscribe to my stories via email to get notified whenever I bring out an article on a new subject.
Thank you for your time and support!!!!
Keep Reading!! Keep Learning!!!
